Wie Large Language Models (LLMs) das Wissensmanagement verändern
24. Mai 2025
Justus Schuster
24. Mai 2025

Wissen gilt als die wichtigste Ressource moderner Organisationen – doch im Alltag zeigt sich oft das Gegenteil. Während Unternehmen Millionen in Tools, Wikis und Datenbanken investieren, bleibt der tatsächliche Zugriff auf relevantes Wissen für viele Mitarbeitende eine Herausforderung.
Das Problem ist nicht der Mangel an Information – sondern der Überfluss.
In der Praxis sieht Wissensmanagement häufig so aus: unübersichtliche Ordnerstrukturen, veraltete Wikiseiten, PDFs aus dem Jahr 2018 und Slack-Kanäle mit 10.000 ungelesenen Nachrichten. Wer wirklich etwas wissen will, muss suchen – und zwar oft länger, als es sich ein Unternehmen leisten kann.
Die Folge:
-
Zeitverschwendung durch redundante Informationsbeschaffung
-
Wissenssilos, in denen Know-how bei Einzelpersonen versickert
-
Fehlentscheidungen, weil kritisches Wissen nicht zugänglich war
-
Demotivation, weil Wissen zwar „da ist“, aber nie dort, wo man es braucht
"Das Wissen ist im System – aber das System weiss es nicht."
Klassisches Wissensmanagement scheitert zunehmend an seiner eigenen Komplexität. Es verwaltet, aber es lebt nicht. Es sammelt, aber es versteht nicht. Und genau hier beginnt die Suche nach einer neuen Antwort – einer, die intelligenter, dynamischer und kontextbewusster ist.
Künstliche Intelligenz als Game-Changer für Wissensorganisation
Wie eine Einschätzung des Frauenhofer IMW zeigt, können klassische Wissensmanagement Systeme Informationen erfassen, aber nicht interpretieren. Sie speichern Inhalte, aber sie priorisieren sie nicht. Sie katalogisieren Dokumente, aber sie verstehen keine Zusammenhänge.
Künstliche Intelligenz (KI) setzt genau an dieser Bruchstelle an. Wo herkömmliche Werkzeuge versagen, bringt KI einen völlig neuen Ansatz:
Nicht mehr Wissen zu sammeln, sondern das richtige Wissen im richtigen Moment verfügbar zu machen. Durch richtige Integration von modernen, intelligenten Archiven sind Arbeitszeit Optimierungen in Höhe von bis zu 19% möglich.
Im Zentrum steht die Fähigkeit, Inhalte nicht nur syntaktisch – also als Wörter oder Dateien – zu verarbeiten, sondern semantisch, also im Sinne. KI-Modelle erkennen Zusammenhänge, filtern Relevanz, priorisieren Informationen nach Kontext – und beginnen damit, Wissen zu strukturieren, statt nur zu speichern.
KI kann
-
Unstrukturierte Daten analysieren und zu nützlichem Wissen destillieren
-
Dokumente, E-Mails, Chats verstehen, clustern und verknüpfen
-
Fragen beantworten, statt Dokumente auszuliefern
-
Veraltete Informationen erkennen und auf Aktualisierungsbedarf hinweisen
Doch das ist erst der Anfang. Denn die wahre Kraft dieser Entwicklung liegt nicht in der allgemeinen Idee von „KI“, sondern in einem ganz konkreten Werkzeug, das derzeit den Ton angibt:
dem Large Language Model – kurz: LLM.
Large Language Models (LLMs) als Schlüsseltechnologie
LLMs bilden derzeit das technologische Rückgrat fortschrittlicher Anwendungen im Bereich Wissensverarbeitung und -bereitstellung.
Was ist ein LLM?
Ein Large Language Model ist ein KI-Modell, das auf der Grundlage grosser Mengen an Textdaten trainiert wurde, um Wahrscheinlichkeiten für Wortfolgen vorherzusagen. Grundlage sind neuronale Netze – meist Transformer-Architekturen –, die durch Mustererkennung in der Lage sind, sprachliche Strukturen, Bedeutungen und Kontexte zu modellieren.
Typische Eigenschaften:
-
Trainiert auf Hunderten Milliarden Wörtern
-
Besteht aus Milliarden Parametern
-
Kann Text generieren, analysieren, übersetzen, zusammenfassen, klassifizieren – in vielen Fällen ohne explizites Training für die jeweilige Aufgabe (→ Zero-/Few-Shot-Learning)
Wie funktionieren Large Language Models (LLMs)?
Um die Fähigkeiten und Grenzen von LLMs im Wissensmanagement sinnvoll einschätzen zu können, ist ein grundlegendes Verständnis ihrer Funktionsweise erforderlich. Dabei geht es weniger um Programmcode oder Hardwaredetails, sondern um die prinzipiellen Mechanismen, die LLMs steuern.
Trainingsdaten und Sprachverständnis
LLMs basieren auf dem Konzept des maschinellen Lernens – konkret: auf Deep Learning mit Transformer-Architekturen.
Trainiert werden sie mit gewaltigen Mengen an Textdaten – je nach Modell mehrere Billionen Wörter – aus Quellen wie:
-
Büchern
-
Websites
-
wissenschaftlichen Publikationen
-
Foren, Wikis, Code-Repositories
-
(und teils firmenspezifischen Dokumenten beim Fine-Tuning)
Ziel des Trainings ist es, die Wahrscheinlichkeit für das nächste Wort in einem Text vorherzusagen, basierend auf dem bisherigen Kontext. Dieser scheinbar simple Mechanismus bildet die Grundlage für komplexe Fähigkeiten wie Zusammenfassen, Argumentieren, Übersetzen oder Dialogführung.
Beispiel: Bei der Eingabe „Wissensmanagement in Unternehmen ist oft…“ lernt das Modell, dass darauf wahrscheinlich Begriffe wie „ineffizient“, „fragmentiert“ oder „datengetrieben“ folgen – abhängig vom restlichen Kontext.
Transformer-Architektur: Der technische Kern
Das „Gehirn“ moderner LLMs ist die Transformer-Architektur (Einführung: Vaswani et al., 2017), die es ermöglicht:
-
Wortbedeutungen kontextabhängig zu modellieren
-
Langfristige Abhängigkeiten in Texten zu erkennen
-
Textsequenzen effizient parallel zu verarbeiten
Ein zentrales Element ist das sogenannte Self-Attention-Mechanismus: Das Modell „achtet“ auf die Relevanz jedes Wortes in Bezug auf andere Wörter im Satz – auch über viele Sätze hinweg. So kann z. B. ein Pronomen korrekt auf sein Bezugswort auflösen oder ein kausaler Zusammenhang zwischen zwei Absätzen erkannt werden.
Tiefere Einblicke in diesen Kern der LLMs , die Transformer Struktur, geben wir hier.
Parameter und Gewichtungen
Ein LLM besteht aus Milliarden von Parametern – intern gespeicherte Gewichtungen, die im Training angepasst werden. Diese Parameter bilden eine Art semantisches Netz, in dem das Modell Bedeutung, Tonalität, grammatikalische Regeln und sogar Weltwissen kodiert.
Die Anzahl der Parameter ist ein Mass für die Modellkapazität – GPT-3 z. B. hat 175 Mrd., GPT-4 mutmasslich deutlich mehr. (Quelle)
Prompting: Steuerung durch Sprache
Nach dem Training wird ein LLM durch sogenannte Prompts gesteuert – Eingaben in natürlicher Sprache, die dem Modell eine Aufgabe definieren. Durch sogenannte zero-shot oder few-shot-Prompts können sogar komplexe Aufgaben ohne weitere Trainingsdaten gelöst werden, z. B.:
-
„Fasse den folgenden Text in drei Sätzen zusammen.“
-
„Welche Gemeinsamkeiten haben die beiden folgenden Artikel?“
-
„Erstelle aus dieser Anleitung ein Schritt-für-Schritt-Tutorial.“
Je präziser der Prompt, desto gezielter die Antwort. Prompt Engineering ist daher mittlerweile ein eigenständiger Kompetenzbereich.
Feinabstimmung & Retrieval-Augmented Generation (RAG)
Zwei Ansätze machen LLMs für unternehmensspezifisches Wissensmanagement besonders wertvoll:
-
Fine-Tuning: Nachträgliches Anpassen des Modells mit organisationsinternen Dokumenten, FAQs, Prozessen etc.
-
Retrieval-Augmented Generation (RAG): Kombination des LLMs mit einer externen Wissensdatenbank. Bei einer Anfrage werden relevante Inhalte dynamisch abgerufen und in die Antwort integriert.
Vorteil: Aktuelle, nachvollziehbare und unternehmensspezifische Antworten ohne Halluzination.
Grenzen & Risiken
Trotz aller Leistungsfähigkeit haben LLMs strukturelle Schwächen:
| Schwäche | Beschreibung |
|---|---|
| Halluzinationen | Das Modell „erfindet“ plausible, aber faktisch falsche Inhalte |
| Bias | Vorurteile aus Trainingsdaten können übernommen werden |
| Mangelnde Erklärbarkeit | Antworten sind oft nicht vollständig nachvollziehbar |
| Kontextgrenze | Nur eine bestimmte Anzahl von Zeichen kann pro Anfrage verarbeitet werden |
| Datenschutz | Bei sensiblen Daten sind Governance und Zugriffskontrolle zentral |
| (Quelle) |
Diese Aspekte müssen bei professionellem Einsatz zwingend mitgedacht werden – z. B. durch Auditierung, Nachvollziehbarkeit, Rollenkonzepte und technische Sicherungsmassnahmen.
Der Einsatz von LLMs im Wissensmanagement
Der Einsatz von Large Language Models im Wissensmanagement macht Informationen nicht nur zugänglicher, sondern auch intelligenter nutzbar. Typische Anwendungen sind interne Wissensassistenten, automatische Dokumentation und dynamische Wissenssysteme. Mit Methoden wie Retrieval-Augmented Generation (RAG) liefern LLMs aktuelle, kontextbezogene und nachvollziehbare Antworten. Durch Personalisierung, Qualitätssicherung und Einbettung in bestehende Systeme entsteht ein lernendes, rollenbasiertes Wissensökosystem – effizient, präzise und zukunftsfähig.
Vom Verstehen zum Umsetzen: Wie Sie jetzt konkret starten
Wer sich mit Large Language Models im Wissensmanagement beschäftigt, steht schnell vor der Frage: _Wo anfangen?_Die Technologie ist komplex, der Hype gross – doch der Einstieg muss das nicht sein. Im Gegenteil: Der sinnvollste Weg liegt nicht im Grossprojekt, sondern im fokussierten Pilot mit klarem Anwendungszweck.
Ein funktionaler LLM-gestützter Wissensprozess lässt sich heute mit relativ geringem Aufwand umsetzen – insbesondere mithilfe sogenannter RAG-Systeme (Retrieval-Augmented Generation). Das Prinzip: Sie verbinden ein LLM mit Ihrem vorhandenen Wissen, ohne das Modell selbst trainieren oder feinjustieren zu müssen.
So starten Sie konkret:
-
Identifizieren Sie realen Use Case, z. B.:
-
Antworten auf interne HR- oder IT-Fragen
-
Zusammenfassung von Dokumenten& Analysen
-
Automatische Protokollierung von Meetings
-
FAQ-Generierung aus Slack-Diskussionen
-
-
**Identifizieren sie relevante Datenmengen
-
Informationen die ohne gute Archivierung verloren gehen
-
Strukturen die viele Vernetzungen beinhalten bieten oft eine grosse Fläche für Optimierungen
-
-
Nutzen sie Archive die sich mithilfe von KI, Blockchain und Automatisierungen zentral ins Unternehmensökosystem integrieren lassen.
-
Testen Sie gezielt:
-
Verwenden Sie realistische Fragen von echten Nutzer:innen
-
Beobachten Sie Antwortqualität, Relevanz, Transparenz
-
Achten Sie auf Schwächen: Auslassungen, Fehler, Halluzinationen
-
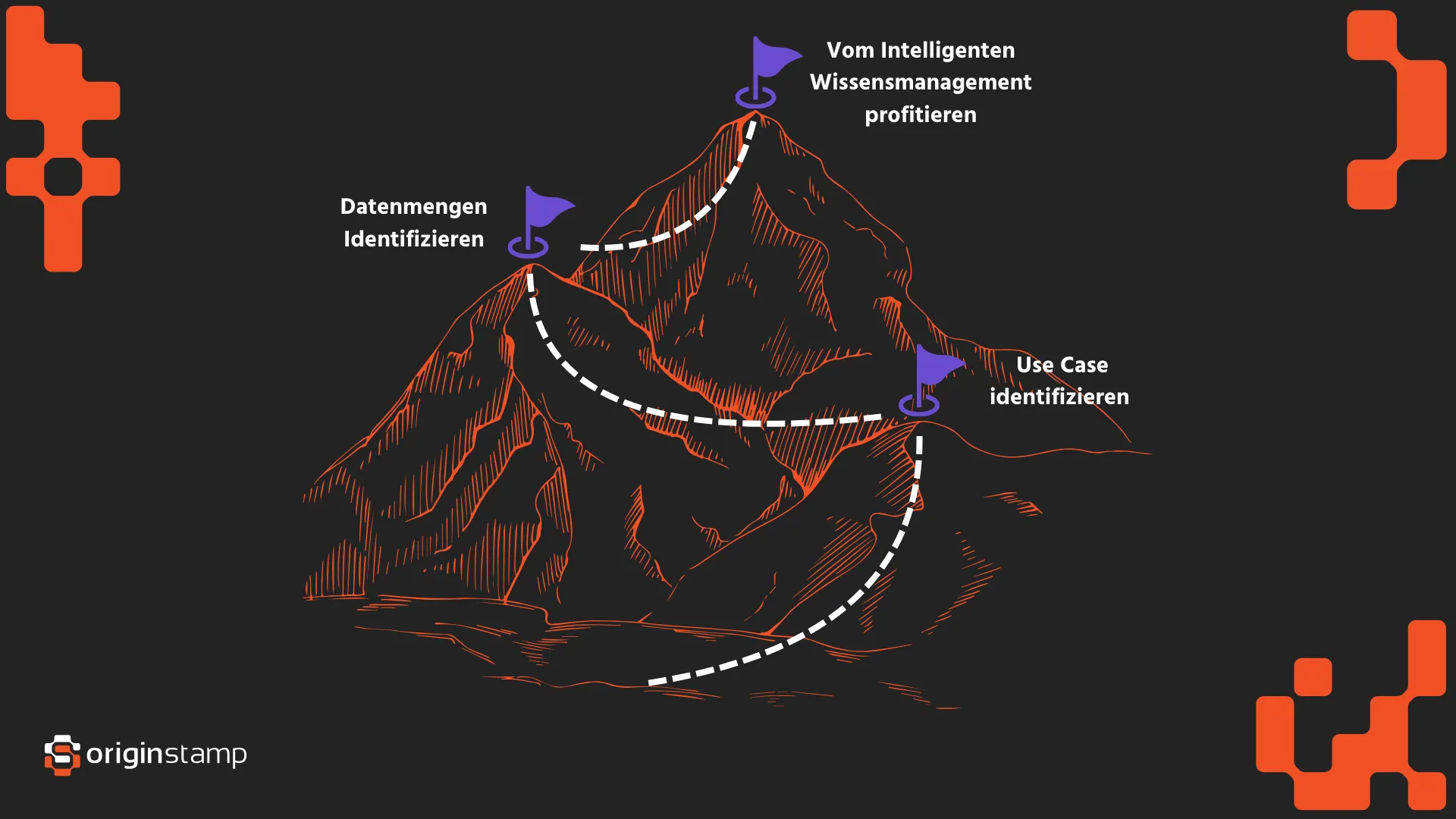
LLMs entfalten ihren Nutzen nicht als Technologiedemonstration, sondern als konkreter Problemlöser im Alltag. Entscheidend ist nicht, ob ein Modell Milliarden Parameter hat – sondern ob es Ihnen hilft, eine echte Wissenshürde im Unternehmen zu überwinden.
Erfahren sie mehr über intelligente Archivierung mit OriginVault.
Eine Idee davon welche Fragen künstliche Intelligenzen mit LLM Grundlage gut beantworten können bekommen sie in unserem Selbstversuch zu den besten Fragen für KI.
Justus Schuster
Marketing
Justus Schuster ist Marketing-Werkstudent bei OriginStamp und unterstützt das Team dabei, technologische Innovationen in klare, fesselnde Inhalte zu verwandeln. Mit einem starken Interesse an Digitalmarketing und kreativer Kommunikation arbeitet er an Content-Strategien, Social-Media-Formaten und Brand-Projekten. Er bereichert das Team durch neue Perspektiven, analytisches Denken und die Bereitschaft, mutig neue Ideen zu testen. Ob Blogartikel, LinkedIn-Beiträge oder kreative Kampagnen – Justus trägt maßgeblich dazu bei, die Technologien von OriginStamp rund um Blockchain-Timestamping, KI-Analysen und digitale Prozessoptimierung sichtbar und verständlich zu machen.

