What Is the Difference Between Dossier Chat and ChatGPT?
Feb 25, 2026
Hanna Lorenzer
Feb 25, 2026

Artificial intelligence is evolving at breakneck speed. Tools like OpenAI’s ChatGPT have become household names. At the same time, more companies are asking a critical question:
Can we use AI without giving up control over our data?
That’s where the Dossier Chat comes in.
If you’re currently researching “What is the difference between Dossier Chat and ChatGPT?”, you’re likely looking for clarity on data security, performance, accuracy, hosting options, and business suitability. This article gives you a transparent, side-by-side comparison – without hype, but with real technical insights.
The AI Dilemma: Generalist vs. Specialist
In the modern workplace, "to ChatGPT" has become a verb for problem-solving. However, ChatGPT is a general-purpose, massive model designed to handle everything from poetry to Python. While impressive, this "jack-of-all-trades" approach introduces significant hurdles for businesses: the risk of data exposure and the tendency for the AI to hallucinate or invent facts when it doesn't know the answer.
The Dossier Chat was developed as a direct response to these specific pain points. It is a single-purpose, specialised system focused exclusively on accurate, fact-based interactions with your specific documents. It doesn't try to be your creative writing partner or image generator; it is built to be a smart and secure digital archivist that merges document storage with the ability to query those files instantly. This focus makes it a competitive alternative for professional use cases where precision is more valuable than creativity.
What Is the Dossier Chat?
The Dossier Chat is a self-hosted, document-focused AI system built specifically to enable secure and accurate interaction with internal documents.
Unlike ChatGPT, it is not a multi-purpose assistant. It has one clear mission:
To allow you to securely talk to your own documents – and only your documents.
It merges two ideas:
-
- A smart archive for storing documents
-
- An AI-powered document query system
The result: a secure environment where you can upload files and ask precise questions without sending data to external providers.
Technical Architecture: A Standalone Powerhouse
While ChatGPT operates as a "black box" hosted on OpenAI's servers, the Dossier Chat is a fully standalone AI system where every operation and process is handled internally. Nothing is delegated to external services or third-party APIs.
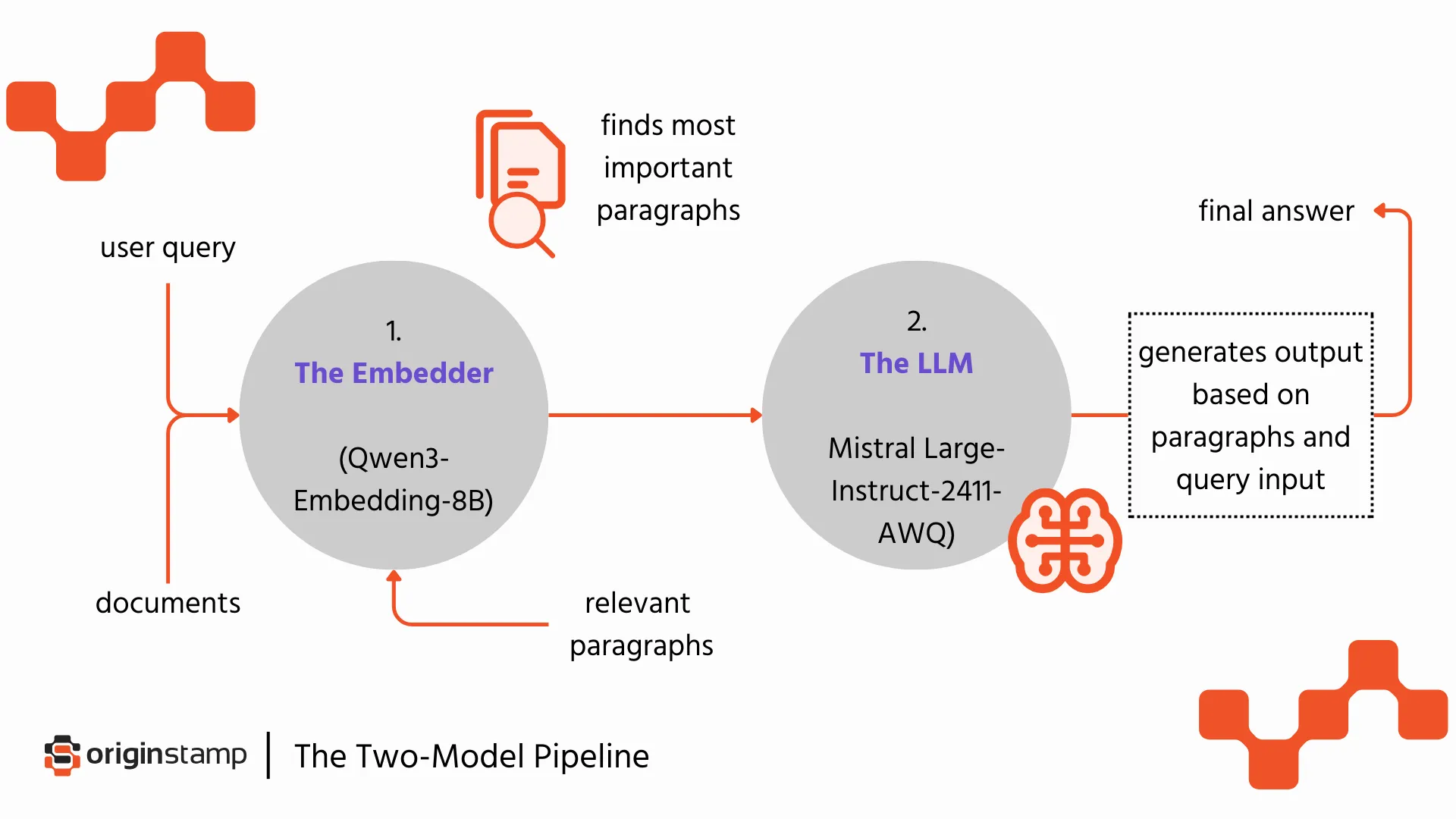
The Two-Model Pipeline
The intelligence of the Dossier Chat isn't based on a single model, but a sophisticated pipeline that ensures precision:
-
1. The Embedder (Qwen3-Embedding-8B): This model is in charge of finding the most relevant paragraphs in your documents relative to your query.
-
2. The LLM (Mistral Large-Instruct-2411-AWQ): This Large Language Model generates the final answer based strictly on the relevant paragraphs found by the embedder and the user's specific query.
Sovereignty and Flexibility
Unlike tools that rely on a fixed cloud provider, the Dossier Chat is highly flexible. Depending on customer needs, it can be hosted on a rented local GPU (as seen with CENT) or deployed on a pay-per-use cloud GPU (like SwiDOC) where you maintain control over the geographic location of the server. This self-hosted nature is what enables the high level of data privacy that commercial alternatives often lack.
Solving the Hallucination Problem with RAG
One of the most frustrating aspects of using general AI for business is hallucination—when an LLM confidently states a falsehood. This often happens because general models rely on their vast training data rather than your specific facts.
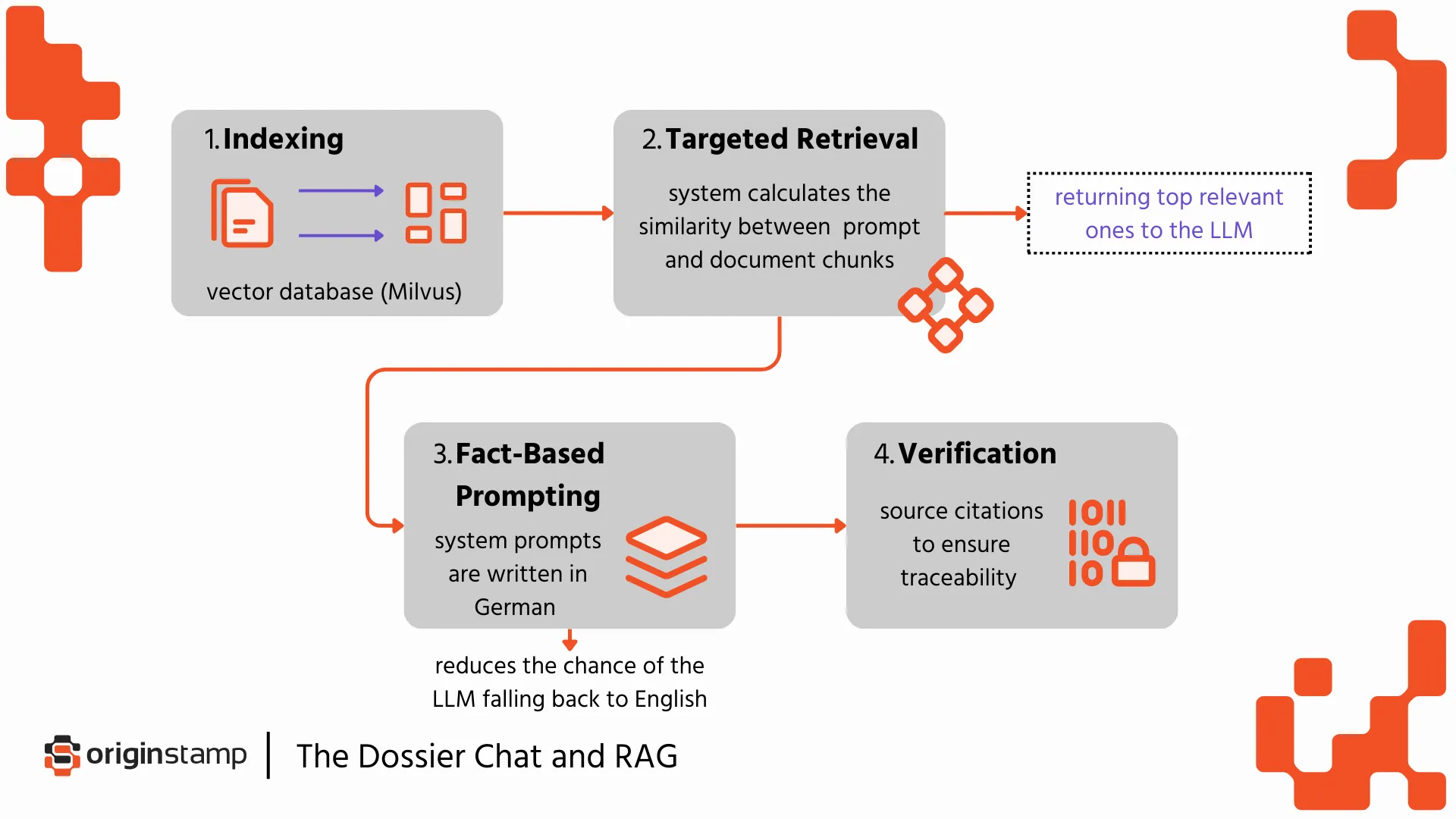
The Dossier Chat combats this using Retrieval-Augmented Generation (RAG).
-
1. Indexing: Your data is "chunked," converted into numbers (embeddings), and inserted into a vector database (Milvus) alongside metadata like filenames.
-
2. Targeted Retrieval: When you ask a question, the system calculates the similarity between your prompt and those document chunks, returning only the top relevant ones to the LLM.
-
3. Fact-Based Prompting: The system prompts are written in German to reduce the chance of the LLM falling back to English and encourage it to base answers strictly on the documents provided.
-
4. Verification: The model is instructed to return source citations at the end of its claims to ensure every statement is traceable.
This targeted context ensures the model sticks to the facts. In internal benchmarks, the Dossier Chat achieved 90% accuracy on public multi-file datasets, while ChatGPT 5 (instant) achieved 83%.
Data Privacy: Why "Stateless" is Safer
For many organisations, the biggest security risks are insider misuse or accidental exposure via external providers. The Dossier Chat is a stateless service, meaning it can only access the files inserted during that specific chat session.
-
- No External Data Transfer: No user inputs or company data are ever sent to external providers like OpenAI.
-
- GDPR Compliance: Because the AI is a self-hosted service connected to a compliant archive, it is GDPR compliant by nature.
-
- Zero Learning: The system does not "learn" from your interactions over time. Every new dossier chat is a clean start-over, ensuring that sensitive information from one project doesn't bleed into another.
-
- Access Control: Access is strictly managed through role-based controls, and system admins only access logs or conversations in cases of incidents or bugs.
-
- Encryption: All client-server communication is strictly encrypted via SSL to protect data in transit.
Strategic Comparison: Dossier Chat vs. ChatGPT
To choose the right tool, you must understand the business limitations and strengths of each approach.
Known Limitations and Operational Realities
While the Dossier Chat offers superior privacy, there are trade-offs to consider in a professional environment:
-
- Manual Synchronisation: The system does not automatically sync with cloud storage or internal drives. Users must manually upload or replace files to keep the "pool" of documents current.
-
- Processing Time: Long context windows (up to 64k tokens) can lead to slower generation. When dealing with approximately 40,000 words, there may be a 15–20 second delay before the AI starts answering.
-
- Format Constraints: The system currently struggles with "dirty" PDFs containing heavy visuals, rotated pages, or highly unstructured Excel files, which can occasionally lead to information being missed or numerical mistakes.
-
- Scaling Costs: Operating the Dossier Chat requires significant GPU resources, costing roughly $5,000 per month for production-level performance.
| Feature | Dossier Chat | ChatGPT |
|---|---|---|
| Primary Use Case | Secure, fact-based document analysis | Creative, coding, general assistance |
| Model Hosting | Fully Self-hosted (Local or Cloud) | External Cloud (OpenAI) |
| Data Privacy | Stateless; no external transmission | Data often used for training/benefits |
| Accuracy | 90% in document-specific tasks | 83% in document-specific tasks |
| Speed | 15–20s start time for large context | Instant / Very Fast |
| Cost Structure | High fixed cost (24/7 service) | Pay-per-use or subscription |
The Future of the Smart Archive
The long-term vision for the Dossier Chat is to bridge the gap between a static archive and a proactive assistant. The goal is for the chatbot to become faster and more insightful, potentially gaining the ability to use URLs, perform web searches, and even execute code for complex numerical analysis.
Because the architecture is built on Python and modern frameworks like vLLM and LlamaIndex, the underlying model can be replaced or updated in as little as an hour to keep pace with the rapidly evolving AI landscape.
Are you ready to talk to your documents without compromising your security? Visit our website that discusses the Dossier Chat.
Hanna Lorenzer
Marketing
Hanna Lorenzer is a working student in Marketing at OriginStamp and strengthens the team through her work in outreach and communication. She develops and executes targeted outreach campaigns, manages contact with external sources, and ensures consistent, clear messaging across all channels. She brings ambition, creative curiosity, and willingness to explore new approaches. With a sharp eye for detail, Hanna edits and refines technical content so it becomes accessible and engaging. She supports the planning and implementation of social media campaigns, contributing ideas for formats, storytelling angles, and campaign structures that align with OriginStamp’s brand.




