AI Governance: Auditing LLM Decision Trails with Blockchain
Mar 11, 2026
Thomas Hepp
Mar 11, 2026
In March 2024, the US Equal Employment Opportunity Commission settled a landmark case against iTutorGroup. The company's AI-powered hiring tool had quietly rejected thousands of applicants over 55 years old — automatically, repeatedly, for months. When regulators came knocking, nobody could produce a complete, verifiable record of what instructions the model had received, what it had returned, or whether those logs had been touched after the fact. The company paid $365,000. The reputational damage was incalculable.
Your legal team thinks your LLM logs are audit-ready. They are almost certainly wrong.
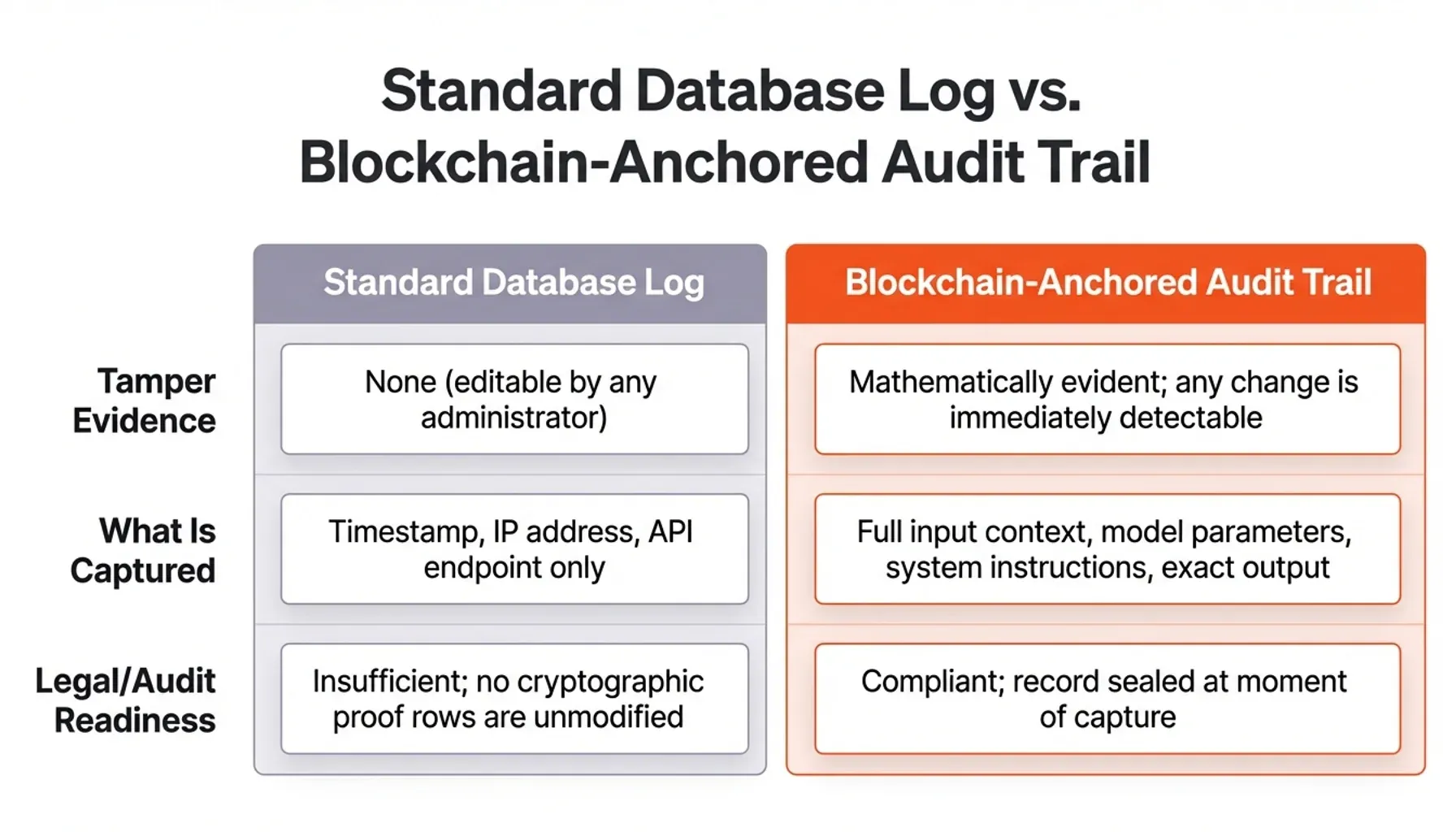
I say that not to be provocative, but because I've seen what "audit-ready" actually means in most enterprise environments: a database table, controlled by your own administrators, with no cryptographic proof that a single row hasn't been touched since it was written. Think of it as a security camera with an editable tape. The footage exists. It looks authoritative. But anyone with access to the recording room can rewind it, cut a few frames, and press play again — and nobody watching the playback will ever know. That's not a safety net. That's a liability waiting to be triggered.
The shift from deterministic software to probabilistic AI is the most significant change in enterprise technology in decades. Traditional software produces predictable, mathematically certain outputs. If a system calculates a financial risk score, the underlying code is a permanent record of how that decision was made. Large Language Models operate on probability. The same input can yield vastly different outputs depending on minor variations in system prompts, model versions, or temperature settings.
When your enterprise deploys an LLM to automate contract analysis, filter job applicants, or generate medical summaries, your organization assumes full liability for every output. Without an immutable record of exactly what data was fed into the model — and precisely what the model returned at a specific millisecond — you are operating blind. You are deploying black-box technology without a verifiable safety net.
The solution is to replace that editable tape with one that can never be touched. Blockchain-anchored audit trails do exactly that: they seal the recording at the moment it's made, so that any subsequent tampering is immediately and mathematically evident. The rest of this article explains how — and why the window for getting this right is closing faster than most compliance teams realize.
The Black Box Problem: Why LLM Transparency is Non-Negotiable
Traditional system logging was designed for a rules-based world. Standard server logs capture timestamps, IP addresses, and API endpoints. They fail entirely at capturing the contextual nuances of generative AI. If your automated HR system rejects a candidate based on an LLM analysis, a standard database log might only show that an API call was executed at 14:00. It won't prove what system instructions were active, what context window was provided, or whether the output was retroactively altered by a system administrator to hide a biased decision.
This lack of algorithmic accountability is no longer just a technical oversight — it is a critical business risk. Regulators are aggressively demanding explainable AI and traceable decision-making. The implementation of ethical guidelines for trustworthy AI has shifted the burden of proof entirely onto the enterprise.
You must now be capable of proving the exact state of an AI interaction during audits or legal disputes. Relying on standard databases that anyone with administrative privileges can modify is insufficient for enterprise risk management. You need to move beyond basic logging and implement a mathematically verifiable AI audit trail. The consequences of getting this wrong under frameworks like the EU AI Act are severe enough to threaten market access entirely.
The Anatomy of a Compliant AI Audit Trail
To achieve true LLM compliance, an audit trail must capture the complete anatomy of an AI decision and seal it mathematically. A compliant log is not merely a text file. It is a comprehensive, tamper-evident data package that reconstructs the exact environment in which an AI generated its response — the full contents of the tape, recorded and locked at the moment of capture.
Building this level of accountability requires capturing four distinct layers of context:
- The Input Context: The exact user prompt, any Retrieval-Augmented Generation (RAG) context injected into the query, and the specific system instructions active at that moment.
- The Model Parameters: The specific model version (e.g., GPT-4-0613), the temperature setting, top-p values, and any other hyperparameters that influenced the probabilistic output.
- The Generated Output: The exact, unaltered text or data structure returned by the LLM.
- The Temporal Anchor: A cryptographic timestamp proving the exact millisecond the transaction occurred, independent of internal server clocks.
Capturing this data is only the first step. What elevates a standard log to a legally defensible audit trail is the mathematical binding of inputs to outputs. You achieve this by creating a cryptographic hash — a unique digital fingerprint — of the entire data package. Using standardized cryptographic hashing protocols, the input and output are permanently bound together. Change a single comma anywhere in the record, and the hash changes entirely, instantly exposing the tampering.
LLM compliance also demands strict adherence to international AI management system standards. These standards mandate immutability, continuous accessibility, and long-term retention of AI logs. Your audit trail must survive system migrations, database updates, and software overhauls — not just the next quarterly review.
Why Standard Logging Falls Short: A Closer Look
Let me be specific about the failure modes, because this is where most enterprise architects underestimate the risk.
A typical enterprise LLM deployment routes requests through an API gateway, logs the interaction to a relational database, and calls it done. The problem is structural. That database sits inside your own infrastructure perimeter. Your DBAs can update rows. Your DevOps team can roll back snapshots. An automated script triggered by a compliance panic at 2am can quietly rewrite history. None of these actions leave a forensically verifiable trace in a standard logging setup.
Now consider what happens when a regulator asks you to prove that the AI output your system delivered to a customer six months ago is identical to what you're showing them today. You pull the database record. But can you prove it hasn't been touched? Can you prove the system prompt active at that moment was the one you claim? Can you prove the model version you've documented is accurate?
If your answer relies on "our internal controls prevent tampering," you are describing a promise, not a proof. Regulators, increasingly, want the latter. In litigation, the difference between a promise and a cryptographic proof can determine the outcome of the case.
This is the gap that blockchain-anchored audit trails close — not by replacing your existing logging infrastructure, but by adding an independent, mathematically verifiable layer on top of it. It's the difference between a security camera with an editable tape and one whose footage is cryptographically sealed the instant it's recorded.
Data Provenance and Dataset Governance
Here's a dimension of AI governance that most enterprises treat as an afterthought — and then regret it. The integrity of an LLM's outputs depends not just on what happens at inference time, but on what went into training and fine-tuning the model in the first place. Data provenance — knowing exactly where your training data came from, how it was collected, and whether it was used with proper consent — is rapidly becoming a hard regulatory requirement, not a best practice.
Collection and Consent
If your organization fine-tunes a foundation model on proprietary data, you need to demonstrate that every dataset used in that process was collected lawfully and with appropriate consent. This is not a hypothetical concern. Litigation over training data provenance is already underway across multiple jurisdictions, and regulators under the EU AI Act explicitly require documentation of the data sources used to develop high-risk AI systems.
In practice, this means maintaining a data lineage record for every dataset: where it originated, under what terms it was collected, whether it contains personal data subject to GDPR or equivalent protections, and what processing was applied before it entered the training pipeline. If you can't answer those questions today, you have a provenance gap — and that gap becomes a liability the moment your AI system is challenged.
Labeling and Annotation Governance
For supervised fine-tuning and RLHF (Reinforcement Learning from Human Feedback) workflows, the quality and consistency of human-generated labels directly shapes model behavior. Annotation governance means documenting who labeled your data, what guidelines they followed, what inter-annotator agreement rates were achieved, and how disputes between annotators were resolved. If a model produces biased outputs, regulators may trace the root cause to labeling decisions — and you need to reconstruct exactly what those decisions were.
Labeling governance also matters for detecting systematic bias introduced at the annotation stage. If annotators applied inconsistent standards across demographic groups, that inconsistency will surface in model outputs. The only way to identify and remediate it is to maintain a complete, auditable record of the annotation process — another frame of tape that must be sealed, not left editable.
Dataset Versioning
Models don't train on static datasets. Datasets evolve — new data is added, problematic records are removed, preprocessing pipelines are updated. Without rigorous version control, you lose the ability to reproduce a specific model's behavior or explain why a model trained at one point in time behaves differently from one trained six months later.
Dataset versioning means treating your training data with the same discipline you apply to source code: tagged releases, change logs, and the ability to reconstruct any historical version on demand. When a regulator asks which version of your training dataset produced a specific model checkpoint, you need a precise, documented answer — not an approximation.
Access Controls and Data Sovereignty
Who can access your training datasets matters as much as what's in them. Unauthorized access to training data — whether by internal actors or external threats — can introduce poisoned data into fine-tuning pipelines, subtly corrupting model behavior in ways that are extremely difficult to detect after the fact. Access controls should follow the principle of least privilege: only the specific teams and automated systems that need access to a dataset for a defined purpose should have it.
Data sovereignty adds another layer of complexity. If your training data includes records from EU data subjects, GDPR applies — including restrictions on cross-border data transfers and requirements for data minimization. Your dataset governance framework needs to map the geographic origin of your data to the applicable legal regimes, and your infrastructure needs to enforce those boundaries technically, not just through policy.
The connection to your audit trail infrastructure is direct. Establishing verifiable data provenance for training datasets uses the same cryptographic principles as logging inference-time interactions: hash the dataset at a specific version, anchor that hash to the blockchain, and you have a tamper-evident record that this exact dataset was used at this specific point in time. When the provenance of your model's behavior is challenged, that record is your evidence.
Governance, Roles, and Accountability: Who Owns What
One of the most overlooked dimensions of AI governance isn't technical — it's organizational. Even the most sophisticated blockchain-anchored audit trail is only as strong as the human accountability structure surrounding it. I've seen enterprises invest heavily in logging infrastructure, then discover during an incident that nobody could answer a basic question: who is actually responsible for this model's behavior?
Sealing the tape is necessary. But you also need to define who controls the camera, who reviews the footage, and who calls the authorities when something goes wrong.
Effective AI governance requires defining clear ownership across four distinct functions:
Model Owner: The business unit or product team that deploys the LLM and defines its use case. The model owner is accountable for the system prompt, the intended scope of the model's decisions, and ensuring that the model is not applied beyond its validated domain. When an LLM drifts outside its guardrails, the model owner is the first line of accountability.
Risk Function: The risk team classifies the AI system under applicable frameworks — EU AI Act risk tiers, NIST AI RMF categories, or internal risk taxonomies. They define acceptable thresholds for model behavior, set escalation triggers, and own the risk register entry for each deployed AI system.
Legal and Compliance: Legal owns the regulatory mapping. They translate framework requirements — retention periods, explainability obligations, human oversight mandates — into specific technical requirements that the model owner and engineering teams must implement. They also own the response strategy when a regulatory inquiry or litigation event occurs.
Security: The security function protects the integrity of the AI pipeline itself: access controls on who can modify system prompts, monitoring for prompt injection attacks, and ensuring that the audit trail infrastructure cannot be compromised by internal or external actors.
Approval Workflows and Human-in-the-Loop Controls
These four functions need a formal RACI matrix — not a vague "AI ethics committee" that meets quarterly, but a documented, operationalized accountability structure with named owners, defined escalation paths, and policy-backed authority. The RACI should explicitly address: who approves changes to system prompts, who can authorize model version upgrades, who receives alerts when anomalous outputs are detected, and who leads the response when an AI incident occurs.
Human-in-the-loop (HITL) controls deserve particular attention. For high-risk AI applications — credit decisions, clinical summaries, hiring recommendations — the governance framework must specify exactly where human review is mandatory before an AI output triggers a consequential action. This isn't just a regulatory requirement under the EU AI Act; it's a practical risk control. A well-designed HITL checkpoint creates a documented moment of human accountability that the blockchain-anchored log can capture: the AI output, the human reviewer's identity, the timestamp of their approval, and the final action taken. That complete chain of custody is what makes an AI-assisted decision defensible.
Approval workflows for model changes are equally important. Every change to a system prompt, model version, or inference parameter should require documented sign-off from the model owner and risk function before deployment. Those approvals should be logged with the same rigor as the AI interactions themselves — because a system prompt change that introduces bias is just as consequential as a biased output, and regulators will want to trace both.
Governance policies must also address the full model lifecycle. That means documented procedures for model onboarding (including pre-deployment risk assessment), model updates (including version-controlled system prompt changes), and model retirement (including log retention obligations that survive the model's decommissioning). An AI system that has been switched off can still generate legal liability years later — your governance framework needs to account for that.
The practical implication is that your blockchain-anchored audit trail doesn't just serve regulators. It serves your own internal governance structure. When the risk function needs to demonstrate that a specific model version was active during a disputed period, or when legal needs to reconstruct the exact system prompt in force at the time of an incident, the immutable record makes that possible. Understanding the full scope of EU AI Act obligations makes the case for this kind of structured accountability even more urgent.
Testing, Monitoring, and Incident Response
Deploying an LLM and anchoring its logs to the blockchain is not the finish line. It's the foundation. The real operational challenge — and the one most enterprises are least prepared for — is what happens after deployment: continuous monitoring, incident detection, and the forensic reconstruction of what went wrong when something inevitably does.
Drift Detection and Behavioral Baselines
LLMs don't stay static in production. Model behavior can shift over time due to upstream model updates from the provider, changes in the distribution of user inputs, or subtle modifications to system prompts that accumulate across iterations. This is model drift, and it's insidious precisely because it's gradual. A model performing within acceptable parameters at deployment may produce systematically biased outputs six months later — and without continuous monitoring, you won't know until a regulator tells you.
Effective drift monitoring requires establishing behavioral baselines at deployment: statistical distributions of output characteristics, sentiment profiles, refusal rates, and decision patterns across demographic proxies. Deviations from these baselines should trigger automated alerts routed to the model owner and risk function. The blockchain-anchored log is what makes this analysis trustworthy — you're comparing current behavior against a tamper-evident historical record, not against logs that could have been quietly adjusted.
Bias and Performance Audits
Bias detection operates on a similar principle to drift monitoring but focuses specifically on differential outcomes across protected characteristics. If your LLM is involved in hiring, lending, or benefits determination, you need automated tooling that continuously tests whether the model's outputs vary systematically by age, gender, ethnicity, or other protected attributes.
Performance audits go further: they assess whether the model is still achieving the accuracy, recall, and precision benchmarks established at deployment. These audits should run on a defined schedule — quarterly at minimum for high-risk applications — and the results should be logged with the same rigor as individual interactions. When bias or performance degradation is detected, the response isn't just to retrain the model. You must produce a forensically sound record of when the issue emerged, which model version was responsible, and what outputs were affected during the window of degraded behavior. That record is what regulators will ask for.
Hallucination Monitoring
Hallucinations — outputs where the model confidently asserts false information — are one of the most acute risks in enterprise LLM deployment. In a healthcare context, a hallucinated drug dosage is a patient safety event. In a legal context, a hallucinated case citation is professional negligence. In a financial context, a hallucinated regulatory requirement could drive a materially wrong business decision.
Monitoring for hallucinations requires a combination of automated fact-checking against authoritative sources, confidence scoring, and human-in-the-loop review for high-stakes outputs. But monitoring alone isn't sufficient — you also need to prove, after the fact, that a specific output was generated by the model and not introduced or modified by a human actor downstream. That's exactly what a tamper-evident audit trail provides: the ability to distinguish between a model error and a human manipulation.
Abuse Detection
Enterprise LLMs are also targets for adversarial use. Prompt injection attacks — where malicious inputs attempt to override system instructions and manipulate model behavior — are a growing threat vector. Users may also attempt to extract sensitive information from the model's context window, bypass content filters, or use the model for purposes outside its sanctioned scope.
Abuse detection requires real-time monitoring of input patterns for known injection signatures, anomaly detection on output characteristics, and rate limiting on unusual usage patterns. When an abuse attempt is detected, the response must be immediate: block the interaction, preserve the full log with its blockchain timestamp intact, and route an alert to the security function. The preserved log becomes the evidence base for any subsequent investigation or legal action.
Incident Response Playbooks
Every enterprise deploying a high-risk LLM application needs a documented incident response playbook — not a generic IT incident process, but one specifically designed for AI failures. The playbook should define, at minimum:
- Incident classification: What constitutes an AI incident? Biased output affecting a protected class, a hallucination that caused material harm, a successful prompt injection, a compliance violation detected by an auditor. Each class should have a defined severity level and a corresponding response timeline.
- Immediate containment: Who has authority to suspend a model's operation? What is the process for doing so without destroying evidence? The blockchain-anchored log must remain intact and accessible throughout the containment phase.
- Forensic reconstruction: The playbook should specify the exact steps for reconstructing the state of the AI system at the time of the incident — model version, system prompt, input, output — using the immutable audit trail. This step should be executable by the compliance team without requiring engineering involvement.
- Regulatory notification: Many jurisdictions require notification of AI-related incidents within defined timeframes. The playbook should map incident classes to notification obligations and assign ownership of the notification process.
- Remediation and post-mortem: What changes are required before the model is redeployed? Who approves those changes? How is the remediation documented and retained as evidence of corrective action?
The blockchain-anchored audit trail is the forensic backbone of every step in this playbook. The immutable timestamp proves when the interaction occurred. The cryptographic hash proves the log hasn't been touched. The sealed record of model parameters proves which version of the model was responsible. Together, they give your forensics team — and your legal counsel — a foundation that can withstand adversarial scrutiny. The same principles that underpin verifiable provenance for AI-generated content apply directly here: the chain of evidence is only as strong as its weakest, most mutable link.
Blockchain AI Governance: The Immutable Trust Layer
The fundamental flaw in modern compliance architectures is the reliance on centralized databases. In a high-stakes scenario — a legal dispute over an AI-generated financial recommendation, say — a standard SQL database offers no mathematical proof of integrity. Administrators, malicious actors, or automated scripts can alter, delete, or fabricate entries without leaving a trace. When the entity hosting the data is also the entity auditing it, you have a conflict of interest baked into the architecture. The security camera and the editable tape are in the same room, controlled by the same people.
Blockchain AI governance solves this by introducing an immutable trust layer that operates independently of any internal administrator or software provider. Every AI interaction receives a permanent digital seal. This creates a model of tamper-evident data integrity where trust is grounded in cryptography, not corporate promises.
The OriginStamp approach is built on 12+ years of development and validated by peer-reviewed traceability research. Rather than storing sensitive corporate data on a public ledger — which would violate privacy regulations — OriginStamp extracts the SHA-256 cryptographic hash of the AI log. This anonymous fingerprint is then anchored to decentralized networks including Bitcoin and Ethereum.
Because the hash is a one-way mathematical function, nobody can reverse-engineer the original data from the blockchain. But your enterprise can use the blockchain transaction to prove, with mathematical certainty, that the AI log existed in its exact current form at that specific point in time. The integrity of your AI decision trail becomes independently verifiable — completely detached from the vulnerabilities of centralized corporate infrastructure.
How Blockchain Timestamping Works in Practice
Here's the mechanics, stripped of jargon.
When your LLM completes an interaction, the full log — prompt, system instructions, model parameters, output — is assembled into a single data package. A SHA-256 hash is computed from that package. This hash, a 64-character string, is what gets submitted to the blockchain. The original data never leaves your environment.
The blockchain network records that hash in a transaction block, which is then cryptographically chained to every block before and after it. Altering that record would require rewriting the entire subsequent chain — computationally infeasible on a major public network. The timestamp embedded in the block is set by global network consensus, not your internal server clock, which means it cannot be manipulated retroactively.
When an auditor or regulator asks you to verify a specific AI interaction, you produce the original log and run the hash function again. If the resulting hash matches the one recorded on-chain, the log is proven unaltered. If it doesn't match, tampering is immediately evident. The verification takes seconds. The proof is absolute. The tape is sealed.
This is not theoretical. It is the same principle used to establish proof of originality for digital assets, and it translates directly to enterprise AI governance.
Strategic Benefits for C-Level Executives
For C-level executives, implementing a blockchain-anchored AI audit trail is not a technical exercise. It is a strategic imperative that directly affects market valuation, risk exposure, and operational scalability.
Risk Mitigation and Liability Reduction Automated decision-making in regulated sectors — HR, Finance, Legal, Healthcare — exposes companies to unprecedented liability. If an AI system makes a biased or financially damaging decision, you must prove exactly why that decision was made and what guardrails were in place. A tamper-evident audit trail provides unalterable proof of the system's inputs and outputs at the time of the event. That proof can be the difference between a manageable settlement and an existential legal battle.
Accelerated Market Access and Compliance Regulatory frameworks are tightening globally. Organizations that proactively align with official EU AI Act requirements ensure uninterrupted market access. A mathematically provable compliance layer lets you meet stringent requirements ahead of schedule, transforming regulatory compliance from a cost center into a competitive differentiator.
Operational Efficiency in Auditing Traditional compliance audits are resource-intensive — often weeks of manual data gathering and verification. With a blockchain-sealed audit trail, internal and external auditors work with ready-to-verify cryptographic fingerprints. This slashes operational overhead and aligns with enterprise technology governance priorities that increasingly demand automated, continuous compliance rather than periodic manual review.
Brand Reputation and Digital Trust In an era of rampant digital manipulation, trust is a premium currency. Proving that your AI outputs have not been retroactively altered builds genuine trust with customers, partners, and regulators. Demonstrating that your organization's digital operations are transparent, credible, and accountable increasingly influences enterprise procurement decisions — and it starts with the integrity of your AI decision records.
Implementation Checklist and Best Practices
Understanding the case for blockchain-anchored AI governance is one thing. Actually building it without derailing your existing operations is another. I've seen well-intentioned implementations stall because teams underestimated the integration complexity, overcomplicated the tooling stack, or failed to account for the performance overhead of hashing at scale. Here's what a practical, production-ready implementation actually looks like.
Tooling Stack
A production-grade AI audit trail typically involves four layers working in concert:
1. Log Capture Layer: Your LLM orchestration framework — LangChain, LlamaIndex, or a custom API wrapper — needs to be instrumented to capture the complete interaction payload before and after each inference call. This means intercepting the assembled prompt (including injected RAG context and system instructions), the model parameters, and the raw output. Don't rely on your LLM provider's native logging — you need logs that you control and that capture the full context, not just the API request.
2. Hashing and Sealing Layer: Once the interaction payload is captured, serialize it into a canonical format (JSON with deterministic key ordering is standard), hash it with SHA-256, and submit it to your timestamping service. OriginStamp's API handles this step, accepting the hash and returning a certificate that links it to the blockchain anchor. This step should be asynchronous — it should not block the response path back to the user.
3. Local Storage Layer: The original log payload — not just the hash — needs to be stored in your own infrastructure with access controls and retention policies applied. The blockchain record proves the log's integrity; your local storage is where the actual content lives. Use append-only storage where possible, and restrict write access to the logging service itself, not to general application or database administrators.
4. Verification Layer: Build a verification endpoint into your compliance tooling that accepts a log record, recomputes its hash, and checks it against the on-chain record. This is what your auditors will use. Make it self-service — the last thing you want during a regulatory inquiry is a manual process that requires engineering involvement to run a basic integrity check.
Performance and Cost Tradeoffs
The most common objection I hear is latency. Hashing and submitting to a timestamping service adds overhead to every LLM interaction. In practice, if you implement the hashing step asynchronously — decoupled from the inference response path — the user-facing latency impact is negligible. The hash computation itself takes microseconds. The API call to the timestamping service typically completes in under 100ms and runs in a background thread.
Cost is a more nuanced question. Blockchain anchoring at the transaction level (one blockchain transaction per log entry) can become expensive at scale on networks with variable gas fees. OriginStamp addresses this through batching: multiple hashes are aggregated into a Merkle tree, and only the root hash is anchored to the blockchain in a single transaction. Each individual log still gets a unique, verifiable certificate, but the on-chain cost is amortized across thousands of records. For high-volume deployments, this is the only economically viable approach.
Storage costs scale with log volume and retention requirements. A full interaction log — prompt, context, parameters, output — for a complex RAG query can easily run to several kilobytes. At millions of interactions per month with ten-year retention requirements under the EU AI Act, storage planning is not optional. Compress logs at rest, tier storage by age (hot storage for recent logs, cold storage for archived records), and ensure your retention management system can handle legally mandated deletion without breaking the integrity of the remaining records.
Common Pitfalls
Logging the wrong thing. The most frequent mistake is logging only the final user-facing output and the raw user input, while omitting the system prompt and injected RAG context. That's like keeping a record of a court verdict without the evidence or the judge's instructions. The system prompt is often where bias and scope violations originate — it must be captured and sealed.
Mutable log storage. Anchoring a hash to the blockchain while storing the original log in a standard relational database with unrestricted write access defeats the purpose. If the log can be altered, the hash mismatch will expose the tampering — but only if someone checks. Build your storage layer so that tampering is structurally prevented, not just policy-prohibited.
No verification workflow. Many teams implement log capture and blockchain anchoring, then never build the verification step. An audit trail you can't verify is an audit trail you can't use. Build the verification workflow before you need it, test it regularly, and make sure your compliance team knows how to run it without engineering support.
Ignoring system prompt versioning. System prompts change. If you don't version-control your system prompts and log which version was active at the time of each interaction, you lose the ability to reconstruct the exact model environment during a disputed period. Treat system prompts like code: version them, tag releases, and include the version identifier in every interaction log.
Underestimating retention complexity. Ten-year retention under the EU AI Act sounds straightforward until you're three system migrations and two cloud providers later. Plan your retention infrastructure for the full required period from day one. Use storage formats and access patterns that will remain viable across technology cycles, and document your retention and deletion procedures in a way that survives staff turnover.
Governance Frameworks and the Regulatory Landscape
It's worth stepping back to understand the regulatory momentum driving all of this, because it's moving faster than most enterprise compliance teams realize.
The EU AI Act, fully in force from 2026, classifies many enterprise LLM applications — particularly in HR, credit scoring, and healthcare — as high-risk AI systems. High-risk classification triggers mandatory requirements for logging, human oversight, and technical documentation that must be retained for a minimum of ten years. The Act explicitly requires that logs be sufficient to enable post-hoc monitoring of the system's operation. Vague database records don't meet that bar.
Beyond the EU, the NIST AI Risk Management Framework in the United States provides a voluntary but increasingly influential blueprint for AI governance. Its GOVERN, MAP, MEASURE, and MANAGE functions all presuppose the existence of reliable, auditable records of AI system behavior. Organizations building compliance programs around NIST AI RMF will find that blockchain-anchored logging satisfies its traceability requirements more completely than any alternative.
Internationally, ISO/IEC 42001 — the AI management system standard — establishes requirements for organizations developing or deploying AI. Certification under this standard requires demonstrable evidence of AI system monitoring and record-keeping. Tamper-evident logs are not optional; they are a certification prerequisite.
The pattern across all these frameworks is consistent: regulators want proof, not policies. They want records that can be independently verified, not assurances from the same organization whose AI system is under scrutiny. Blockchain timestamping transforms your internal records into independently verifiable evidence — sealed tape that nobody can edit. And as global AI governance frameworks continue to converge around these principles, the organizations that have already built this infrastructure will be setting the standard — not scrambling to meet it.
Practical Implementation: Integrating OriginVault into AI Workflows
Understanding the necessity of an AI audit trail is only half the equation. Frictionless implementation is what drives enterprise adoption.
For ERP vendors, healthcare software providers, and industrial SaaS platforms managing thousands of end-customers, building a bespoke compliant archiving and blockchain timestamping system from scratch is a multi-year, resource-draining endeavor. Most organizations don't have that runway — especially when regulators are already knocking.
This is where OriginVault functions as the critical compliance and archiving engine. Designed specifically for software vendors with extensive user bases, OriginVault provides an invisible, white-labeled compliance layer. ERP and SaaS vendors integrate LLM compliance directly into their existing platforms, saving years of development time while delivering enterprise-grade data integrity to their end-users.
The technical workflow is designed for maximum security and minimal latency. When an end-user triggers an AI action within the ERP system, the platform makes an API call to OriginVault. The system captures the complete AI interaction log and immediately applies an AES-256 data seal. This encrypted package is then processed through the OriginStamp core technology, generating a SHA-256 hash that is permanently anchored to the blockchain. Even system administrators with full database access cannot modify the sealed documents without breaking the cryptographic signature and triggering an immediate alert.
OriginVault is built on a robust multi-tenancy architecture, allowing ERP vendors to manage thousands of separate customer environments within a single instance. Data sovereignty is strictly maintained. The infrastructure is cloud-agnostic — deployable on AWS, Azure, or on-premises — and anchored in Swiss infrastructure, ensuring the highest standards of digital privacy.
True compliance also requires mastering the complete data lifecycle. OriginVault autonomously manages complex retention periods and audit-proof deletion protocols in strict accordance with GDPR, GoBD (Germany), and certified compliance standards including GeBüV (Switzerland). AI logs are preserved exactly as long as legally required, then mathematically destroyed when retention periods expire, leaving no residual risk.
Thomas Hepp
Co-Founder
Thomas Hepp is the founder of OriginStamp and creator of the OriginStamp timestamp, which has set the standard for tamper-proof blockchain timestamps since 2013. As one of the earliest innovators in the field, he combines deep technical expertise with a pragmatic focus on solving real business problems, and is a recognized voice in blockchain security, AI analytics, and data-driven decision support. His work has earned multiple international awards, including a top Best Project recognition from ETH Zurich and the Swiss Confederation. He publishes regularly on blockchain, AI, and digital innovation.




