Preventing Data Poisoning: Ensuring ML Data Integrity
Mar 11, 2026
Thomas Hepp
Mar 11, 2026

The Silent Threat to AI: Understanding Data Poisoning
Picture this: a hospital's diagnostic AI has been quietly reviewing chest scans for months. Radiologists trust it. Administrators celebrate its efficiency. Then a researcher notices something disturbing — under a very specific set of conditions, the model consistently misclassifies malignant tumors as benign. Not randomly. Systematically. Someone, at some point, fed it corrupted training data, and the model learned exactly what the attacker wanted it to learn.
No firewall was breached. No malware was deployed. The attack happened in the data itself.
Here's the uncomfortable thesis: we have spent a decade hardening the walls of our systems while leaving the food supply completely unguarded. Enterprises have invested billions in endpoint security, zero-trust architecture, and intrusion detection — yet the datasets feeding their most critical AI decisions often sit in loosely governed pipelines with minimal verification. Attackers have noticed. The battlefield has shifted toward adversarial machine learning, where the goal isn't to breach a system but to corrupt what it believes.
This phenomenon — training data poisoning — is arguably the most underestimated vulnerability in enterprise AI today. In financial services, a poisoned dataset can train an algorithmic trading model to ignore specific market signals, triggering catastrophic automated losses or systematically biased loan approvals. In healthcare, the tumor scenario above isn't hypothetical; it's a documented attack class. And in fraud detection, an attacker who flips just a handful of labels can teach a model to wave through exactly the transactions it should block.
Understanding the threat landscapes facing AI systems demands a fundamental rethink of how organizations ingest, process, and secure their data. Without mathematical proof of data authenticity, you're trusting your most critical automated decisions to a black box built on an unverified foundation.
Anatomy of an Attack: How Secure Training Sets Are Compromised
To defend against data poisoning, you first need to understand how attackers actually pull it off. Unlike traditional malware, poisoned data doesn't execute malicious commands. It corrupts the statistical patterns a model relies on — quietly, invisibly, by design.
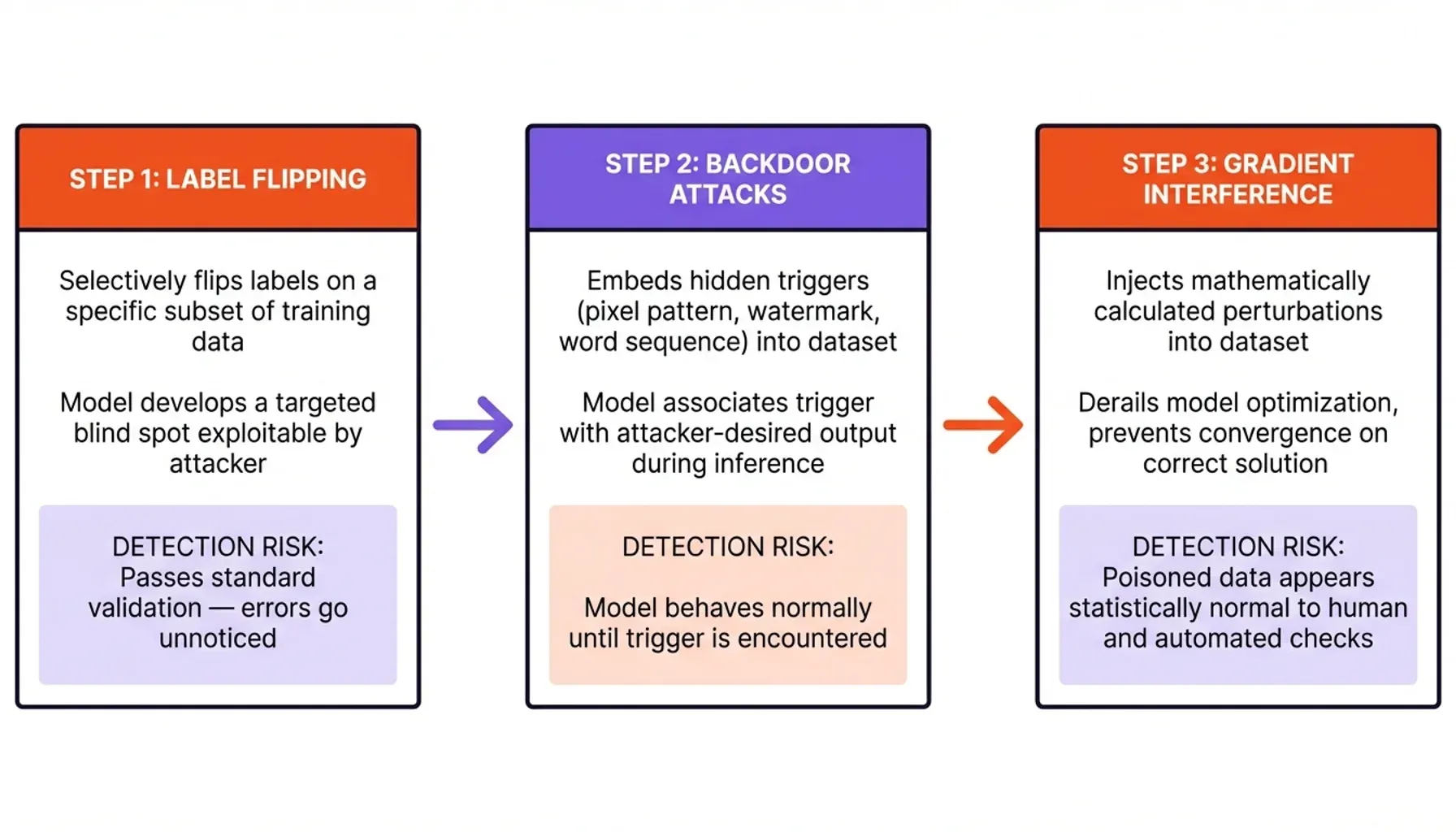
Label flipping is one of the most prevalent techniques. In supervised learning, models depend on accurately labeled examples to learn classifications. An attacker with access to the training pipeline selectively flips labels on a specific subset of data. In a fraud detection system, for instance, they might relabel a particular type of fraudulent transaction as "legitimate." The model learns this incorrect pattern and develops a blind spot the attacker can later exploit at will. Because these poisoning attacks maintain overall accuracy on normal inputs, the systematic errors often go entirely unnoticed during standard validation testing. The model passes every benchmark. It just fails exactly where the attacker needs it to.
Backdoor attacks are more surgical. Here, attackers embed hidden "triggers" into the dataset — a specific pixel pattern in an image, a hidden watermark in a document, a unique word sequence in a text corpus. During training, the model learns to associate that trigger with a target output. During inference, it behaves perfectly normally — until it encounters the trigger, at which point it bypasses all standard logic and delivers the attacker's desired outcome. From the outside, the model looks fine. Internally, it's been compromised.
Gradient interference is the most technically sophisticated vector. Attackers inject mathematically calculated perturbations into the dataset, actively derailing the model's optimization process and preventing it from converging on the correct solution. Research into neural network vulnerabilities shows exactly why these attacks are so difficult to catch: poisoned data often looks statistically normal to both human reviewers and automated checks. The corrupted files don't contain viruses. They contain mathematically optimized deception.
Data Provenance AI: Tracking the Digital Lifecycle of Training Data
To fight training data poisoning, organizations are turning to Data Provenance AI — the practice of establishing an unbroken, verifiable history for every piece of information used in the ML lifecycle. From the moment a data point is ingested, through every transformation, to its final inclusion in a training batch, its journey must be mathematically trackable.
The cornerstone of this approach is an immutable audit trail. When enterprise datasets are aggregated from dozens of internal systems, third-party vendors, and public repositories, maintaining a clear chain of custody becomes genuinely hard. Data Provenance AI tackles this by logging the exact origin, transformation history, and access records of every dataset. Using tamper-evident blockchain frameworks, organizations can create a cryptographic fingerprint for large-scale datasets at any point in time. If a single byte changes, the fingerprint changes — and administrators get an immediate alert.
This level of tracking is essential for eliminating "shadow data" — unauthorized, undocumented information that silently slips into training pipelines. Shadow data is a primary poisoning vector precisely because it bypasses standard quality assurance. By enforcing strict provenance specifications and tracking standards, enterprises ensure that only verified, authenticated data influences their models.
Maintaining AI content provenance across the entire data ecosystem isn't just a technical nicety — it's the difference between assuming your data is safe and mathematically proving it is. When every dataset modification ties to a specific, unalterable timestamp, you've moved from trust to proof.
Strategic Defense: Building Robust ML Data Integrity
Securing enterprise AI requires a multi-layered defense strategy that goes well beyond access controls. You need ML pipelines that actively resist, identify, and neutralize poisoned inputs before they corrupt the final model.
Data Sanitization is your first line of defense. Advanced statistical outlier detection identifies and filters potentially malicious inputs before they reach the training phase. By analyzing dataset distribution, sanitization algorithms flag anomalies that deviate from expected patterns. But here's the catch: sophisticated poisoning attacks are specifically designed to mimic normal data. Sanitization alone isn't a silver bullet. It must pair with continuous monitoring and dynamic threshold adjustments to keep pace with the attack methodologies documented in recent machine learning security research.
Robust statistics during training are equally critical. Traditional ML optimization often relies on mean-based aggregators — and those are highly susceptible to skewed data. A single extreme outlier injected by an attacker can shift the mean enough to corrupt the model's understanding entirely. Switching to median-based aggregators and trimmed means makes the training algorithm inherently more resilient to injected noise. Even if a fraction of the training set is compromised, the core model logic holds.
Differential Privacy adds another layer. Originally designed to protect individual user identities within large datasets, it has proven highly effective against poisoning attacks. By injecting mathematically controlled noise into the training process, differential privacy prevents the model from memorizing specific, isolated data points. Even if an attacker successfully inserts a backdoor trigger, the model is statistically unlikely to memorize and act on it — effectively neutralizing the attack before it can fire.
Human-in-the-loop verification remains indispensable despite all of this automation. Automated systems can highlight statistical anomalies. Only human context can determine whether an anomaly represents a novel market trend or a sophisticated poisoning attempt. Expert validation of sanitization outputs isn't overhead — it's insurance.
Privacy and Compliance Implications: PII, Consent, and Audit Readiness
Here's a dimension that rarely gets enough attention in data poisoning discussions: the intersection of ML data integrity with privacy law and regulatory compliance. These aren't separate concerns. They're deeply entangled — and getting this wrong can expose your organization to liability that dwarfs the cost of any security breach.
Training datasets frequently contain personally identifiable information. Customer transaction records, medical imaging metadata, user behavioral logs — all of it can carry PII, often inadvertently. When that data flows into a training pipeline without proper governance, you're not just creating a security risk. You're potentially violating GDPR, HIPAA, CCPA, or whichever jurisdiction applies to your users. The moment PII enters a training set, you inherit a set of obligations: lawful basis for processing, data minimization, purpose limitation, and the right to erasure.
That last one is particularly thorny for ML teams. If a user exercises their right to be forgotten, can you actually remove their data's influence from a trained model? In most architectures today, the honest answer is: not easily. This is why consent and retention policies must be designed into the data pipeline from day one, not bolted on afterward. Every data point entering a training set should carry provenance metadata that includes its consent status, its permissible use cases, and its scheduled retention window. When a deletion request arrives, you need to know exactly where that data touched your pipeline — and have a documented process for handling it.
Audit readiness is the other side of this coin. Regulators increasingly want to see not just that your model performs well, but that the data it learned from was lawfully obtained, properly governed, and traceable. This means maintaining records that answer specific questions: Who collected this data? Under what consent framework? When was it ingested? What transformations did it undergo? Who had access? These aren't questions you want to reconstruct after the fact during an investigation.
Cryptographic timestamping directly supports audit readiness. When every dataset ingestion event, transformation step, and access record is anchored to an immutable blockchain timestamp, you have a defensible, tamper-evident record that regulators and auditors can independently verify. This is precisely what frameworks like ISO/IEC 42001 are beginning to mandate — documented, verifiable evidence of data governance practices, not just policy documents.
The practical implication for engineering and compliance teams: treat your ML data pipeline as a regulated supply chain. Every input needs a label. Every transformation needs a receipt. Every model training run needs a manifest. The organizations building these habits now will be dramatically better positioned when the next wave of AI regulation arrives — and it's coming faster than most compliance teams realize. Understanding what those regulatory penalties actually look like should be enough to make this a board-level priority.
Cryptographic Anchoring: The Role of Blockchain in AI Security
Statistical defenses and sanitization are crucial — but they don't provide definitive proof of data authenticity. To achieve true ML Data Integrity, you need to prove that your datasets haven't been tampered with at any point in their lifecycle. That's where cryptographic anchoring becomes the ultimate arbiter of truth.
Here's how it works. You process a dataset through a hashing algorithm — SHA-256, for instance — to generate a unique, fixed-length string of characters. This hash acts as a digital fingerprint. Change even a single comma in a terabyte-sized dataset, and the resulting hash changes entirely. Anchor that hash to a public blockchain like Bitcoin or Ethereum, and you've created mathematical proof of existence at a specific moment in time.
Why does this matter more than standard internal logging? Because server logs and database records are mutable. An attacker who gains administrative access can alter the training data and then rewrite the logs to cover their tracks. A blockchain fingerprint is decentralized and immutable — even the highest-level system administrator cannot retroactively alter it. The cryptographic proofs anchoring the data remain trustworthy regardless of what happens inside your network.
This same logic applies to model weights. Once a model is trained, you hash its specific neural weights and biases and anchor that hash to the blockchain. Before deploying to production, the system automatically verifies that the model weights match the anchor — confirming that what you're deploying is exactly what was trained on your verified, untampered dataset. No surprises. No substitutions.
OriginStamp's approach to this challenge delivers scalable, enterprise-grade infrastructure. Its API-driven timestamping process lets organizations integrate SHA-256 anchoring directly into automated ML pipelines — ensuring every dataset, every training run, and every model deployment is backed by immutable cryptographic proof. For a deeper look at how this infrastructure scales across the enterprise, it's worth exploring how data integrity practices are evolving in 2025.
Compliance and Governance in the Age of Adversarial AI
The technical challenges of data poisoning are colliding with strict new regulatory frameworks — and the collision is happening faster than most enterprises are prepared for. As AI systems take on increasingly critical roles, regulators are demanding unprecedented levels of transparency, accountability, and data quality. ML Data Integrity is no longer just a security issue. It's a core compliance mandate.
Legislation now requires providers of high-risk AI systems to ensure their training, validation, and testing datasets are relevant, representative, error-free, and complete. Failure to meet these standards carries severe financial consequences. The official mandates on artificial intelligence require organizations to demonstrate that their data governance practices are functionally resilient against adversarial manipulation — not just theoretically sound.
Traditional compliance standards for audit-proof archiving — GoBD in Germany, GeBüV in Switzerland — are now being applied to machine learning training logs. If an AI system makes a decision that leads to legal action or financial loss, your organization must produce an immutable audit trail proving exactly what data the model trained on and how it reached its conclusions. "We think the data was clean" is not a legal defense.
Preparing for AI audits requires a robust security framework built around verifiable evidence. This means aligning internal development practices with management system standards for artificial intelligence and ensuring risk management protocols are both thoroughly documented and cryptographically verifiable. For VPs of Engineering and Chief Risk Officers, deploying auditable LLM decision trails is the most reliable way to demonstrate compliance and protect the organization from liability when — not if — an audit arrives.
The Future of Trust: Proving Model Authenticity
The era of black-box AI — where models process unknown data and output decisions without explanation or accountability — is ending. The future belongs to transparent, verifiable AI. As poisoning attacks grow more sophisticated, the organizations that can mathematically prove the authenticity and integrity of their models will hold a genuine competitive advantage. Not just in security, but in customer trust, regulatory standing, and operational resilience.
Achieving this requires a commitment to digital sovereignty. Relying on opaque, third-party data lakes without independent verification is a critical vulnerability. Swiss-based infrastructure and decentralized blockchain anchoring ensure that your proof of integrity remains independent of any single cloud provider or vendor. This aligns with global initiatives prioritizing trustworthiness in automated systems — the expectation that technology serves its users reliably and safely, and can prove it.
For engineering teams operating in continuous deployment environments, here's a non-negotiable checklist:
- Cryptographically hash all incoming datasets upon ingestion.
- Anchor data hashes to a public blockchain to establish an immutable timeline.
- Implement robust statistics and differential privacy during model training.
- Hash and anchor final model weights before production deployment.
- Continuously verify production models against their cryptographic anchors to detect drift or tampering.
- Document consent status, retention policies, and PII handling for every dataset entering the pipeline.
Trust in AI cannot rest on software promises or vendor marketing. It must be built on facts, immutable records, and mathematical proof. Secure the digital lifecycle of your training data, and you protect your infrastructure from adversarial attacks while ensuring your proof of data originality stands up to any audit, threat, or regulatory inquiry that comes your way.
Thomas Hepp
Co-Founder
Thomas Hepp is the founder of OriginStamp and creator of the OriginStamp timestamp, which has set the standard for tamper-proof blockchain timestamps since 2013. As one of the earliest innovators in the field, he combines deep technical expertise with a pragmatic focus on solving real business problems, and is a recognized voice in blockchain security, AI analytics, and data-driven decision support. His work has earned multiple international awards, including a top Best Project recognition from ETH Zurich and the Swiss Confederation. He publishes regularly on blockchain, AI, and digital innovation.




