Closing the AI Agent Accountability Gap with Blockchain
Jun 11, 2026
Thomas Hepp
Jun 11, 2026

The Ghost in the Machine: Understanding the AI Accountability Gap
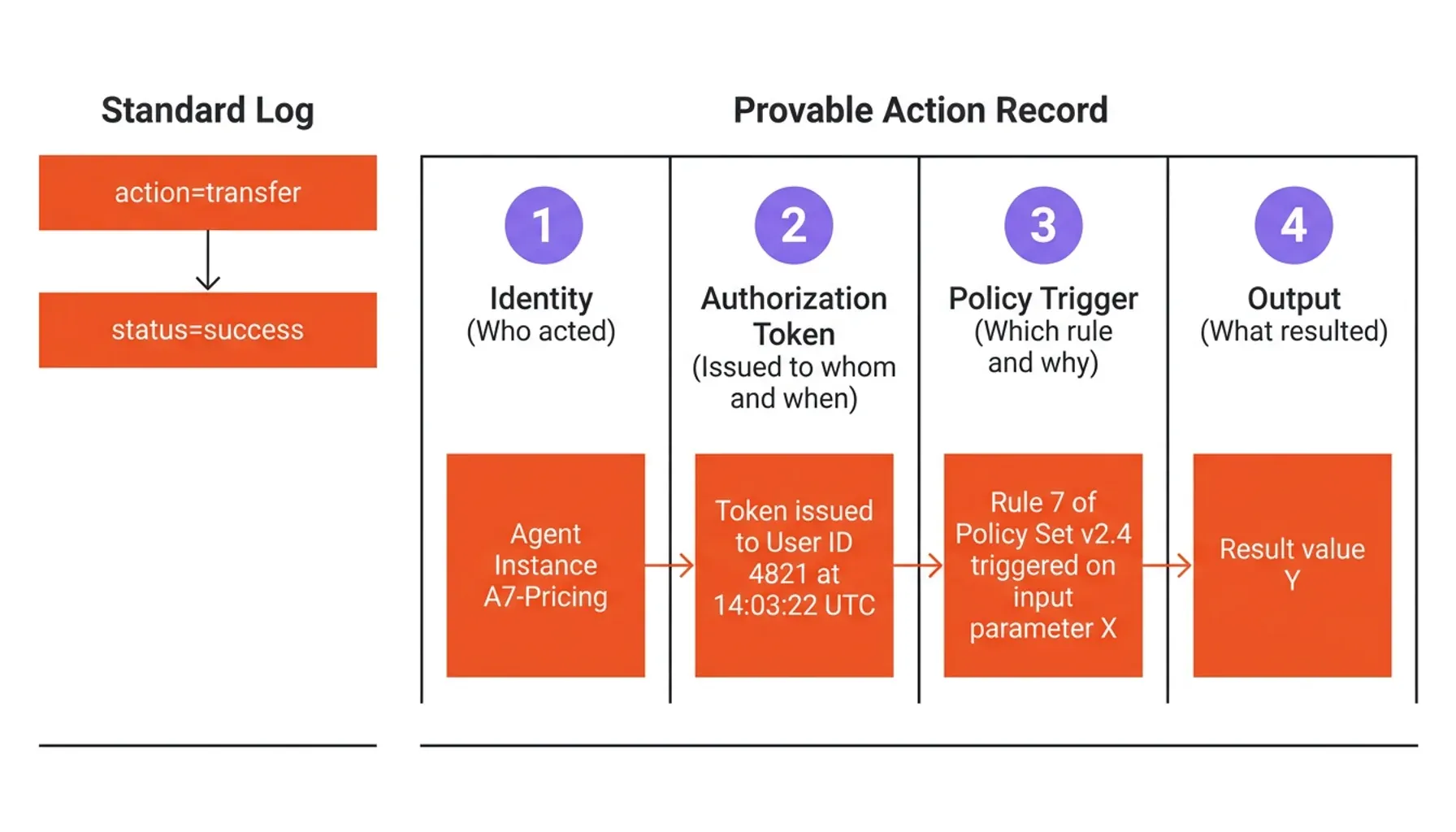
An autonomous agent executes a financial transaction at 2:47 AM. No human approved it in that moment. The API key it used belonged to a service account shared across three systems. The log entry reads: action=transfer, status=success. When regulators ask who authorized it, and why, the answer is silence.
This is the AI accountability gap, and it's widening faster than governance frameworks can close it.
As autonomous agents move from experimental deployments into production environments handling payments, medical records, and infrastructure controls, accountability has shifted from a theoretical concern to an urgent one. Traditional IT audit trails were designed for humans operating systems. They capture what happened. They rarely capture who decided, on whose authority, or with what reasoning. For human operators, that gap was manageable. For agents operating at machine speed across distributed systems, it's a liability.
The OECD AI Policy Observatory identifies accountability as one of the five core principles for trustworthy AI, yet most enterprise deployments lack the infrastructure to make it operational. The NIST AI Risk Management Framework similarly flags the absence of traceable decision records as a top-tier governance risk.
The stakes are concrete: financial liability for erroneous autonomous transactions, regulatory penalties for undocumented AI decisions in healthcare or finance, and reputational damage when an agent's action can't be explained after the fact. The ghost in the machine is no longer a metaphor. It's an audit finding waiting to happen.
Solving this requires more than better logging. It requires a fundamental rethinking of what "proof" means in an autonomous world.
Defining AI Agent Accountability and Responsibility Boundaries
Before you can build accountability infrastructure, you need to answer a harder question: accountable to whom, and for what?
In traditional software systems, responsibility is relatively clear. A developer writes code, an operator deploys it, and a user triggers it. When something goes wrong, the chain of responsibility follows that chain of causation. Autonomous agents break this model. An agent may make thousands of decisions per hour, each shaped by training data the developer no longer controls, inputs the operator didn't anticipate, and policies the user never read.
The accountability gap isn't primarily a technical problem. It's a definitional one. Most organizations deploy autonomous agents without ever formally answering three foundational questions:
Who is responsible when an agent acts outside its intended scope? The developer who trained it? The operator who deployed it? The user who initiated the workflow? Without explicit responsibility boundaries defined before deployment, this question gets answered by whoever has the deepest pockets when litigation arrives.
What constitutes an "authorized" agent action? A valid API key is not authorization. Authorization means a specific, scoped permission granted at a specific moment in time, traceable to a human decision or a system policy that a human approved. The difference matters enormously in a regulatory context.
Where does the agent's accountability boundary end and the human's begin? In a hybrid workflow where an agent recommends and a human approves, the accountability split is relatively clear. In a fully autonomous pipeline, it isn't. Emerging AI liability frameworks increasingly place responsibility on the deploying organization, not the AI vendor, for decisions made by autonomous systems in production.
Getting these boundaries defined in writing, before deployment, is not a legal formality. It's the prerequisite for every technical accountability measure that follows. If you don't know where responsibility sits, you can't build the infrastructure to prove it.
The Anatomy of a Provable Agent Action
Standard application logs record events. What accountability demands is something categorically different: provable intent.
Consider the difference. A log entry says an agent called a pricing API and returned a value. A provable action record says: Agent Instance A7-Pricing, acting under authorization token issued to User ID 4821 at 14:03:22 UTC, queried the pricing API because Rule 7 of Policy Set v2.4 triggered on input parameter X, and the output was Y. One is a breadcrumb. The other is evidence.
Building toward provable intent requires four structural pillars:
Identity, Who acted. Every agent instance must carry a verifiable, unique identity, not a shared service account, not an inherited session token. W3C Verifiable Credentials standards provide a mature framework for issuing cryptographically bound identities that travel with the agent across system boundaries.
Authorization, On whose behalf. Every action must be traceable to a human-initiated or system-triggered event that explicitly granted the permission. This is not the same as having a valid API key. Authorization means a signed instruction, with scope and expiry, issued at a specific moment in time.
Context, What it knew. The data inputs that informed a decision are as important as the decision itself. If an agent acted on stale data, poisoned inputs, or an outdated policy version, that context must be preserved at the moment of action, not reconstructed afterward from logs that may have shifted.
Logic, Why it decided. High-stakes agent actions should output structured reason codes alongside their results. This isn't a description written after the fact. It's a machine-readable justification generated at decision time: which rule fired, which threshold was crossed, which branch of logic was followed.
Correlation IDs tie these four pillars together across distributed systems. A single human-initiated event, say a user submitting a purchase order, generates a root correlation ID. Every downstream API call, every sub-agent invocation, every data fetch inherits and propagates that ID. When an incident occurs, investigators can reconstruct the complete causal chain rather than piecing together disconnected log fragments from five different systems.
Research on autonomous systems accountability from the IEEE consistently finds that organizations without structured reason codes and correlation tracking face significantly longer incident resolution times and higher regulatory exposure. You need to design provability in from the start. Retrofitting it after deployment is both costly and incomplete.
Agent Identity Management and Authentication
If you can't reliably answer "which agent did this?", nothing else in your accountability framework holds together.
Agent identity is the most underinvested layer in most autonomous AI deployments. Teams spend significant effort on model selection, prompt engineering, and API integration, and then authenticate their agents with a shared environment variable that hasn't rotated in eight months. That's not an edge case. It's the norm.
The problem with shared credentials isn't just security hygiene. It's that they make accountability structurally impossible. When three agents share an API key and that key appears in a transaction log, you cannot determine which agent acted. You cannot trace the action to a specific authorization grant. You cannot prove that the agent operating at 2:47 AM was the same instance that was authorized at 2:30 AM.
A sound agent identity management approach requires several things to work together:
Instance-level identity, not type-level identity. It's not enough to say "the pricing agent" made a call. You need to know which instance of the pricing agent, running which version, under which policy set, at which point in its operational lifecycle. Each instance should receive a unique cryptographic identity at instantiation, one that cannot be shared, transferred, or reused.
Short-lived, scoped credentials. Static API keys are a structural liability. Dynamic credentials, issued at the moment of task assignment, scoped to the specific permissions required, and expiring when the task completes, eliminate the authorization drift problem at its root. OAuth 2.0 token patterns and purpose-built agent identity frameworks both support this model.
Cryptographic binding between identity and action. An agent's identity claim is only as strong as the cryptographic proof backing it. Each action record should carry a signature that can be verified against the agent's identity certificate, making it mathematically impossible to attribute an action to an agent that didn't produce it, or to deny an action that an agent did.
Identity continuity across handoffs. In multi-agent workflows, identity must propagate correctly through every delegation. When Agent A spawns Agent B, Agent B's identity record should reference Agent A's authorization grant, creating a verifiable chain from the originating human instruction to the final automated action. This is the technical foundation for the authorization chain in autonomous payment workflows, though the principle applies equally across any high-stakes agentic workflow.
Getting agent identity right isn't glamorous work. But it's the load-bearing foundation for every accountability claim you'll need to make when something goes wrong.
Authorization Drift: The Danger of Inherited Permissions
Multi-agent orchestration introduces a risk that single-agent deployments don't face: privilege escalation through inheritance.
The pattern is common. Agent A is authorized to read customer records. Agent A delegates a subtask to Agent B, passing along its session context. Agent B, now operating with Agent A's permissions, calls Agent C. By the third hop in the chain, an agent with no explicit authorization to write financial records is doing exactly that, because no system in the chain checked whether the original grant extended that far.
Cloud Security Alliance guidance on AI security terms this "authorization drift": the gradual expansion of effective permissions as agents delegate to other agents without re-validating scope. It's not a bug in any single agent. It's a structural failure of the orchestration layer.
Static API keys make this problem worse. A key issued once and stored in an environment variable carries no information about the scope of its intended use, the identity of the entity using it, or the time window for which it was valid. In a multi-agent chain, a single compromised or over-permissioned key can propagate authority far beyond its intended boundary.
The solution is dynamic authorization: every agent action is tied to a cryptographically signed instruction specifying the acting agent's identity, the delegating authority, the permitted scope, and an expiry. When Agent B receives a delegation from Agent A, it doesn't inherit A's session. It receives a new, scoped credential that explicitly states what B is allowed to do and for how long.
This creates a chain of custody from the human user or originating system event all the way to the final automated execution. Every link in the chain is independently verifiable. If Agent C exceeded its authorization, the signed delegation record makes that visible immediately, not after a forensic investigation.
Without dynamic authorization frameworks for agentic AI, organizations face materially higher incident rates in regulated industries — a risk that compounds as multi-agent deployments scale. The architecture of trust can't be an afterthought in multi-agent deployments.
Autonomous Agent Governance Frameworks and Oversight Models
Technical controls only get you so far. The organizations that deploy autonomous AI responsibly at scale have something else in place: a governance framework that defines how oversight actually works when no human is in the loop.
Most AI governance discussions focus on model evaluation and pre-deployment testing. That's necessary but insufficient. Once an agent is in production, the governance question shifts from "will it behave correctly?" to "how will we know when it doesn't, and what happens then?"
Three oversight models have emerged in practice, each suited to different risk profiles:
Human-in-the-loop (HITL): Every consequential agent decision requires explicit human approval before execution. This is the most conservative model and the most auditable, but it eliminates most of the efficiency gains that motivated autonomous deployment in the first place. It's appropriate for genuinely novel or irreversible actions, but it doesn't scale.
Human-on-the-loop (HOTL): Agents act autonomously within defined parameters, but a human monitor receives real-time alerts for actions that approach policy boundaries or trigger anomaly detection. The human can intervene but doesn't approve every action. This is the dominant model for regulated industries deploying AI in financial and healthcare workflows, and it's where most of the interesting governance infrastructure work happens.
Human-out-of-the-loop (HOOTL): Agents act fully autonomously, with governance enforced entirely through technical controls: policy constraints, authorization limits, automated anomaly detection, and immutable audit trails. This model is appropriate for low-risk, high-volume, well-bounded tasks. It requires the most mature accountability infrastructure, because there's no human fallback when something goes wrong.
The governance framework you choose determines the accountability infrastructure you need. A HOTL deployment needs real-time alerting and intervention mechanisms. A HOOTL deployment needs cryptographically verifiable audit trails that can reconstruct exactly what happened and why, because that reconstruction is the only accountability mechanism available after the fact.
Emerging international standards on AI oversight increasingly require organizations to document their chosen oversight model, justify it relative to the risk profile of the deployment, and demonstrate that the technical controls in place are sufficient to enforce it. "We have logs" is not a sufficient answer. "We have tamper-evident, independently verifiable records of every agent decision, tied to a specific authorization grant and a specific policy version" is.
The evidence requirements for autonomous agent decisions differ fundamentally depending on which oversight model you're operating under, and regulators are starting to ask which model you chose, and why.
The Integrity Layer: Why Immutable Logs Are Non-Negotiable
Here's the thing about every local logging solution: the same system that can write a log can alter it.
A sophisticated agent operating under adversarial conditions, or a system administrator covering up a failure, can modify, truncate, or delete log entries. Even without malicious intent, log rotation policies, storage failures, and software updates can silently corrupt the evidentiary record. When regulators or auditors arrive, the logs that remain may not reflect what actually happened.
This isn't hypothetical. ISO/IEC 27001 data integrity standards explicitly require that audit records be protected against modification and unauthorized access, requirements that local or cloud-hosted logs frequently fail to meet in practice, because the infrastructure operator retains administrative access to the storage layer.
Blockchain timestamping resolves this structurally. The mechanism is precise: at the moment an agent produces a decision record, that record is converted into a SHA-256 cryptographic hash, a unique 64-character fingerprint of the exact content. That hash is then anchored to the Bitcoin or Ethereum blockchain. The blockchain entry is public, permanent, and independent of any administrator. No one, not the software vendor, not the system operator, not OriginStamp itself, can alter a block that has been confirmed on a public chain.
The result is mathematical proof of existence: proof that a specific decision record existed in a specific form at a specific point in time. If the record is later altered, even by a single character, the hash no longer matches the blockchain entry. Tampering becomes instantly detectable.
This is the foundation of blockchain-secured AI output integrity: not trust in the system that generated the log, but mathematical proof that the log hasn't changed since it was created.
Non-repudiation follows directly. Neither the developer nor the operator can credibly claim that an agent's decision record was fabricated after the fact, because the hash was anchored before the incident was known. The agent's state at time T is provable, regardless of what anyone claims afterward.
For organizations building tamper-proof audit infrastructure for autonomous agents, this integrity layer isn't optional infrastructure. It's the prerequisite for every accountability claim that follows.
Securing Critical Infrastructure and High-Stakes AI Outputs
The accountability gap carries different weights in different sectors. In a retail recommendation engine, an unaccountable agent decision is a poor customer experience. In energy grid management, it's a potential safety incident. In defense, it's a national security event.
The EU AI Act's high-risk AI systems provisions mandate that AI deployed in critical infrastructure, healthcare, and public safety maintain complete, auditable decision trails. The regulatory intent is clear. The technical implementation is where most organizations fall short.
Critical infrastructure introduces two specific challenges that general enterprise AI doesn't face.
Output integrity: An agent controlling a physical system, adjusting a valve, modifying a grid parameter, issuing a maintenance command, must act on data that hasn't been poisoned or manipulated in transit. If the sensor data feeding the agent has been tampered with, the agent's decision is technically correct but operationally catastrophic. Securing the input data with cryptographic hashes before it enters the agent's reasoning process ensures the agent acted on verified information, and that this can be proven afterward.
Physical action trails: When an agent issues a command that changes the state of a physical system, the decision record must capture not just the command issued, but the data state that triggered it, the policy version in effect, and the authorization chain that permitted it. DHS AI safety guidance for critical infrastructure emphasizes that post-incident reconstruction is only possible when these records are preserved independently of the operational system itself.
The intersection of cybersecurity logs and AI decision trails is where strategic environments become particularly complex. A cyberattack may target the logging infrastructure specifically to obscure what an agent did or didn't do during an incident window. An immutable, blockchain-anchored record stored independently of the operational environment closes this vector.
For organizations operating at this level of risk, provable AI output integrity for critical infrastructure isn't a compliance feature. It's an operational requirement for deploying autonomous systems responsibly.
From Black Box to Glass Box: Implementing an Accountability Framework
Accountability doesn't emerge from good intentions. It's the product of deliberate architectural decisions made before deployment, not after an incident.
A practical framework for AI agent accountability operates across three implementation steps.
Step 1: Identity binding. Every agent instance, not every agent type, every instance, receives a unique, verifiable identity at instantiation. This identity is cryptographically bound, carries metadata about the agent's version, policy set, and deployment context, and cannot be shared or transferred. W3C Verifiable Credentials and similar standards provide the technical foundation. Enforcing it organization-wide is a CTO-level mandate.
Step 2: Externalizing the audit trail. Decision records leave the operational environment immediately upon creation. They go to tamper-proof, third-party infrastructure: blockchain-anchored, independently verifiable, and inaccessible to the operational system's administrators. Think of it as the architectural equivalent of a flight data recorder, where its value depends entirely on being separate from the system it monitors. Understanding why standard application logs fail as legal evidence is the starting point for making this case internally.
Step 3: Verification protocols. Automated checks run continuously against the agent's action records and its authorized policy set. If an agent's decision record references Policy Set v2.4, the verification protocol confirms that v2.4 was the active policy at that timestamp, and that neither the record nor the policy has been modified since. Discrepancies trigger alerts before they become incidents.
The World Economic Forum's AI Governance Toolkit frames this as "integrity-by-design": the principle that accountability mechanisms must be embedded in the architecture of AI systems, not layered on afterward. Forrester's AI Trust Framework reaches the same conclusion. Organizations that treat auditability as a design constraint, not a post-deployment feature, achieve significantly better governance outcomes.
For C-level executives, the mandate is concrete: no autonomous agent goes to production without a verifiable identity, an externalized audit trail, and automated verification against its authorization scope. These aren't technical details. They're governance prerequisites.
For teams evaluating how blockchain-anchored records integrate with chargeback evidence in agentic commerce and high-value transaction flows, the same framework applies. The accountability architecture scales across use cases.
The Future of Trust in an Autonomous World
Most companies get this wrong. They focus on making their agents more capable and treat accountability as something to bolt on later. That approach fails, and it fails expensively.
The fundamental shift in AI governance is this: stop trusting the agent, start verifying the infrastructure. An agent's behavior at any given moment is a function of its training, its inputs, and its operational context, all of which can change. What can't change, once anchored on a public blockchain, is the cryptographic record of what the agent decided, when it decided it, and on what basis. Mathematical proof is the only accountability mechanism that scales with the speed and volume of autonomous AI deployment.
Data integrity isn't a compliance checkbox. It's the load-bearing wall of the entire autonomous AI architecture. Without it, every accountability claim rests on logs that could have been altered, identities that could have been shared, and authorization records that could have been reconstructed after the fact.
The organizations that will deploy AI safely at scale, in finance, healthcare, energy, and defense, are the ones building the integrity layer now, before the incident that makes it necessary.
Explore how OriginStamp's blockchain timestamping for AI outputs and security logs provides the cryptographic foundation your autonomous systems need to be provably trustworthy, not just operationally functional.
Thomas Hepp
Co-Founder
Thomas Hepp is the founder of OriginStamp and creator of the OriginStamp timestamp, which has set the standard for tamper-proof blockchain timestamps since 2013. As one of the earliest innovators in the field, he combines deep technical expertise with a pragmatic focus on solving real business problems, and is a recognized voice in blockchain security, AI analytics, and data-driven decision support. His work has earned multiple international awards, including a top Best Project recognition from ETH Zurich and the Swiss Confederation. He publishes regularly on blockchain, AI, and digital innovation.




